Like any contrived example it might be too simple and too silly to really show the power of implementing the pages this way, but here is a short walk-through of the flow anyways:
The view loads the presenter with a reference to itself and asks it to PresentAllDogs:
The view just assigns a local field with the values retrived (in some scenarios it might be doing a databind or similar, all depending on how the template aspx is used):
1234
publicvoidRenderDogs(IList<Dog>dogs){Dogs=dogs;}
When the template is rendered it automatically renders the Dogs from the view:
This way of rendering is my preferred as it puts just the right amount of rendering logic in the template. It does not work well if you need to manipulate specific rows of the table and have the viewstate handle which you clicked.
For this you could use the listview control which is a decent compromise between using raw template rendering and having the view set values on elements using the runat server tag (I definetely prefer the first template rendering.)
In the next couple of blog posts I will try to outline how I try to improve the maintainability and testability of pages written in the ASP.NET Web Forms framework
Don’t use ASP.NET Web Forms
If you are not forced there is no good reason to use this technology. There are many better ways to write your web applications. If you wish to work with the .NET framework you might consider:
ASP.NET MVC latest incarnation (if it just has to be Microsoft)
Nancy (nice open source framework)
… and other options
If your wish to use something other than .NET there are also many options (the reason I base this decision on whether you want .NET or not is simply because we started out discussing alternatives to Web Forms):
RAILS, Sinatra, Goliath and other options on Ruby.
Django on Python.
Node.js potentially with the express framework.
… and lots of other options.
Point is: First way to improve your Web (Forms) code is to not use Web Forms.
I Have no Choice
If you are stuck building Web Forms, it is most likely due to working on a legacy system build with this technology. There are lots of those out there and they are not getting upgraded to better options (at least not all of them).
Thus, we have to manage somehow.
The main tactic I advocate for coping with the platform is a pattern called MVP (Model-View-Presenter): MVP(Go down a bit to find the description)
Now this may not be the most easily accessible description and potentially you might not be able to implement the pattern in your application from this description (or it would require quite some work).
There is a catch to the pattern though. If used correctly it can help make your code more testable and easier to reason about, but it adds complexity and will not save you from having to know about viewstate, page lifecycle and other details about Web Forms.
Bits and Pieces
Not surprisingly we need a class for each of the roles of Model, View, and Presenter (actually a bit more).
Model
The model is just a PONO (plain old .NET object) and can be your domain model or alternatively a view model. When to use a view model is largely a matter of taste, but I prefer not to do it unless I actually use it for something as it does add an overhead of an extra class and mapping code (consider using a tool like automapper if you do have both models).
View
The view in our ASP.NET webform MVP implementation is basically our code behind file and the aspx file can be considered a template for helping with rendering the html. The key is to keep the code behind file very very slim as the view can typically be very hard to test due to dependencies on ASP.NET.
The responsibility of the view is to render html, retrieve values from the html (really being the viewstate), and kicking of the flow (that is the way webforms work).
The view is hidden by an interface to save the Presenter from knowing the gritty details of webforms. This way the presenter could also be used in another application that is not necessarily for the web.
The view initializes the presenter with a reference to the view itself – typically in the pageload event, but that really depends on the purpose of the page.
Presenter
The presenter is somewhat similar to the Controller in the MVC pattern, at least in the way I use it. It is not triggered in the same way as in MVC, though, as the view has to start it up.
Basically, the presenter handles the flow of the page, receiving data from the view when an event occurs (a button is clicked for instance), using lower level constructs (like data-layers or services) to manipulate data and then typically asking the view to render something. I would never have a presenter function return a value, as it is solely up to the presenter to determine what the view should do (not how though).
The presenter will get a reference to the view through the interface in the constructor.
In .NET this leaves us with 5 pieces:
A View (for instance SearchDogView) which inherits from System.Web.UI.Page.
A template used for rendering html for the view (the ASPX file).
Since the beginning of the year I have been working on building a new REST based API to be consumed by both internal and external clients in Node.js.
The main reason for choosing node and mongo as the main elements in our stack when we started the project was to alleviate a number of pains we experienced with the “old” stack of ASP.NET and SQL. Most of this was related to the amount of ceremony that goes in to doing even simple stuff on that stack, which was being made worse by the way the technologies were used. Most if not all of these pains were indeed alleviated, but we gained a couple of new ones, which can be mitigated to some extend.
Debugging and Stack Trace
Having spent many hours the last couple of weeks debugging errors in an application with a codebase that is gaining in size I have come to the conclusion that simply put, the debugging and stack trace in node is inferior to what you would get in a .NET based environment.
I have found some of the error messages to be short non descriptive and very generic, making it often fairly hard to understand what is going on. Likely, it is a consequence of the lack of maturity of the technology combined with the lesser experience I have with it, but reading a stack trace in .NET would often mean I know exactly what the problem was, which is not the case with node.
Probably, the callback nature of most of the API’s also is somewhat to blame for this.
Most of these challenges can be minimized with a good and solid test suite, as it can help pinpoint more precisely where an error has occurred.
A nice little addition to this is that the dynamic nature of the language means simple spelling mistakes in parts of the program that is not executed by tests (bad!) will not get caught. This is an easy problem to fix though – apply JSHint, JSLint, or similar (do it from day one, you owe it to yourself).
I tried to find a good “bad” error message to put here, but could not easily provoke one intentionally. Will keep a look out for it and make a new post next time I find a good one.
Integration vs Unit Tests – Design and Architecture
The way our application is designed means it is mostly implemented using express middleware stack with a little bit of business logic sprinkled here and there. We quickly discovered that this was probably not the best architecture, but still have some leftovers and we have had some challenges to write code that can be unit tested in a meaningful way (without a ton of mocks and fake objects being build).
This is mainly a design challenge and not a consequence of node, nor javascript, but it has lead to a side effect. Because the “units” are not easily testable, a large percentage of the codebase is mainly tested with integration style tests using “restler” (I would actually recommend using “request” instead). These tests are as good or even better than unit tests to find errors, but (un)fortunately the error data returned from our API does not give me enough information to pinpoint what goes wrong.
Thus, the conclusion I have come to is that the middleware should be extremely thin and always defer the bulk of the implementation to another module that can tested. This goes both for middleware implementing cross-cutting concerns and the actual end-point implementation.
The platform does not have a large body of known design patterns for implementing maintainable applications. This easily leads to developers trying out a lot of different approaches with different merits and flaws, which means the codebase could suffer from inconsistencies making it hard to maintain.
Hosting
Figure out very early how you are going to host this. If you are going for a cloud based hosting vendor and you are based in the States, there is a number of options.
The same options are available in Europe, but from the States, leading to a latency challenge. Trying to get a solid agreement with a hosting partner in Europe has been hard and we have been forced to settle for a worse agreement that we would like.
The good part is that due to the traction of the platform almost everyday a new option pops up, and we can always fallback to running off amazon or azure and managing the setup ourselves.
Picking the right Stack
Node.js has been gaining a lot of traction and combined with some of the prime modules it is in general a very nice stack for building the kind of API we are building. I would pick it again if I had to make the choice again today, but this time with the knowledge of what is brings.
It has taken longer, and been harder than expected (was almost expected), but we are getting close to being done and can reflect upon what worked and what did not work.
Get JSHint or JSLint up and running (as early as possible).
Get CI up and running (as early as possible) – not after 4 months when you are trying to finish up the project.
The design and architecture is really important – do not let the speed with which you can whip up new features keep you from worrying about this. Design for tests that can tell you what is wrong with the application when changes are being made.
Decide as early as possible on standards (to enforce the design and architecture decisions), and make sure the application follows these before moving on. I would recommend starting out with the revealing module pattern, hoisted functions for callback nesting, avoiding control flow libraries such as async, avoiding inheritance, considering every used external module very carefully, and most importantly keeping it dead simple.
Start out with testing hosting setups from day one:
Deploy your app to different platform as service vendors, such as:
Deploy your app to amazon or similar – if nothing else to get an idea of how the server actually work and what is required.
Use these experiments to figure out how you want to run your application in production. Figure out which are “ real” requirements and which are nice to have.
Consider before you start whether to use CoffeeScript or javascript to write the application. It might seem like a straight forward choice to you, but at least do yourself the favor of spending just a little bit of time researching.
The last 3 months or so I have been busy working on a new backend built in node with mongo as the database. It has been lots of fun, with some frustration, and lots of heureka moments.
This is my attempt at describing those experiences, some good and some bad.
The two many reasons we opted to work with node was the following:
Development speed, due to the simplicity of node and using the same language in both client and server.
Performance, most of the information we found indicated that we could easier get more performance from using node than the alternative of ASP.NET.
Development Speed
It seems like the development speed has indeed been increased, but in reality we cannot really measure before we build the next module on top of node. Our first module has also been the proving grounds for the technology stack, as the maturity of the technology means there is not so much information to find on how to write the best node code. Thus, the progress has most likely been slower than what we can expect in the future (yet I still believe I have seen an improvement compared to old projects).
Same Language
So node being javascript, it is in fact the same language is we use in our browser client (built on top of backbone). But, due to the fact that node does not work in the same way as the browser with regards to the code it is not completely trivial to share code between server and client.
A given file containing a function in node would have to use
1
module.exports=myFunction;
To expose it to being available for use elsewhere. In addition this file would have to be required for the code to actually be used elsewhere. One could argue this is much better than the browser where the same function would probably be attached to some global object (pretending to be a namespace).
To give an example of how one could implement code usable for both browser and node, I have taken the liberty of showing a snippet from the brilliant underscore library doing exactly this:
Having a cross OS platform gives us more freedom in which development machines to use and servers to run in production, which also gives us more freedom regarding hosting partners, whether in the cloud or not. Actually, all the developers are working on windows, as we have found the Webstorm IDE to be the best tool by far, and it does not work well on linux (when that linux is a virtual box at least.
Running development on windows and production on linux has not been without problems though. The node core is equally good on both OS, but some of the modules we have used have not been properly tested on windows. Additionally, the windows file system is case insensitive, while it is case sensitive on linux, which has led to one error deployment so far.
Pyramid of Doom
Much have been written about the problems the callback nature of most node api’s lead to. Our solution has been to mainly use function hoisting:
This is working ok for scenarios where we have a fixed depth of nesting of functions (the example with 2 above is not a bad pyramid of doom by the way – try throwing in a couple of more levels of nesting and you will see the problem). Unfortunately, this method does not work with a dynamic level of nesting (think an array of functions generated and to be called in sequence), and this is where a library such as Async can help.
Solving the pyramid of doom this way has not been without challenges, as there have been arguments about using Async or similar library even with a fixed amount of nesting. My standing on this is that code written with Async in that scenario (fixed level of nesting) is much harder to read, understand, and reason about.
Express and middleware
Like most developers doing services in node exposed on the web, we have chosen the express web framework. There are a lot of features built into express, and to be honest we only use a fraction of them. Mainly the middleware stack (from the connect sub module) has been used for good, but certainly also for bad.
Cross cutting concerns like logging, authorization, and gzipping are all examples where benefit can be reaped from the stack and it is easy to apply a certain behaviour to all requests and responses. Unfortunately, the ease of implementation has lead to data access and business logic being implemented as middleware. This went well for a while, but it is harder to reuse and test the middleware as they are dependent on the (request, reponse, next) – triple of arguments, as opposed to business relevant objects.
Thus, we are moving towards not using middleware for data access and business logic, having one function, registered as middleware, for each end-point which then delegates to business and data oriented modules.
Require (Cyclic)
As we move along and introduce more files and more modules, I have noticed a tendency to let all dependencies be resolved with require. This leads to some scenarios where we have fairly low level functionality (such as configuration api) require high level functionality (the user module). This easily leads to cyclic require loops, causing bugs that can be hard to resolve. Like any software it is good practise also in node to let high level functionality depend on low level functionality – not the other way.
The solution to reusing bits is, as with many frameworks, to divide and conquer. If a high level module contains a function that would be really usable in a low level module, extract it in a seperate module and break the cycle that way.
Return Callback
Just an observation on the nature of some of the node code I have been writing recently:
123456
functiondoSomeStuff(err,callback){if(err){callback(err,'bad stuff happened');}callback(null,'wuhuuuu bad stuff did not happen');}
Did you find the bug? This is the most simple example I could come up with, but when it gets a bit more complex I find myself forgetting the return statement in front of the first callback, leading to some funky debugging session:
123456
functiondoSomeStuff(err,callback){if(err){returncallback(err,'bad stuff happened');}callback(null,'wuhuuuu bad stuff did not happen');}
Maybe it is just a quirk of how many brain process the code, but consider yourself warned! ;-D
Simplicity
This is the one point where I believe node really shows its strength, it is dead simple to implement a server. Recently, we had a potential candidate who had written the server part of his test in less than 100 lines of coffee-script, and I really think this says it all.
Performance
I have written a lot about my experiences with developing on node, and very little regarding the awesome earth-shattering speed of node.
Some claim that the way node works (event-loop and such) is the coolest thing since the invention of the wheel, while others claim that it is borderline stupid. I am not going to join that discussion, but just tell that what I have seen so far and the experiments done show that node is indeed fast, and also faster than what we did before. That being said our team does not have good large scale measurements or experiments of our own to prove this.
Is node the best choice available for us? Maybe, it could be, but at least until now it has proven to be a very good choice.
One thing I have noticed after working on a Backbone powered application for 4 months is that developers have very different views on how to split a screen mockup into Backbone views in the code.
I have seen re-use of code with each and every input field being wrapped by a view and named as a control (…smells like ASP.NET web forms controls – shudders….) and potentially you could also have all the markup handled by one view.
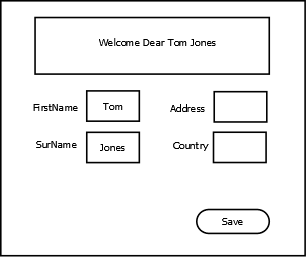
Given a small example screen mockup for gathering simple information about a person, like this:
Lets try to look at the different ways we could implement this with Backbone views, but first let us look at the requirements:
There is a message area that greets the person when the full name has been given (should be triggered when the user leaves either field if both are filled), and similarly the message area will contain errors if something goes wrong when clicking the save button.
FirstName and SurName only allows characters (yes I am aware this excludes some people with dots in names or similarly). This should be checked when leaving the field.
Country is actually a dropdown that lists the Scandinavian countries.
With these requirements in hand we have a couple of options for implementation.
Not using Backbone at all.
Will save us the trouble of having to worry about Backbone, but since we are building this form within a Backbone powered application and it does contain several things that could benefit from Backbone this is probably not the best idea.
Using one template with all markup for this screen and one Backbone view.
This is probably a very good first implementation, with the clear benefits of having a template that is easy to read and style, but unfortunately we will also have a view that does not adhere to the Single Responsibility Principle (SRP).
Using a view with a template for every single item on the screen
This option removes all readability of the markup as it is broken into a multitude of very small fragments, and you will probably end up with a view for the entire screen with a render method like this:
Somewhere in between all the crazy options given above the solution can be found. Maybe what we really want is a view corresponding to the screen, a view for the message area, a view for the area with the input fields, and potentially a view for the save button. It will adhere to SRP in my opinion and the markup with be in fragment sizes that are possible to mentally combine and get the overview.
It leaves us with the problem of the input area – what about the validation, binding to the model etc?
In third option this was most likely handled by the InputView.
I would suggest keeping the markup in the template, possibly enriching it with just enough information to enable binding dynamically to the model (consider using or stealing the idea of something like backbone.modelbinding). Apply the binding jQuery style at the last line in the render method (only one line) and use jQuery to find all elements requiring binding.
Thus:
Be careful with fragmenting the backup for a screen too much. It really reduces the overview.
Don’t use a view if you do not need one. A simple javascript module or function would do.
Leave the markup intact and decorate it for dynamically enriching it with behavior. In the ideal scenario your markup would work if javascript was disabled (albeit this does not make much sense in a Backbone application).
Your render method should be a matter of rendering a template and calling at most one method for each dynamic behavior required: modelbinding, autocomplete in some fields, or similar.
So finally the time has come where we have decided to give the node and mongo combination a closer look at my work. Not that we are going to migrate everything to such a platform tomorrow, but the combination of node and mongo is so promising that we decided to give it a try to see how far we can get.
Basic Setup
This is the setup we are going for sofar (will probably change as we get smarter – please feel free to help with that):
Virtual Box on windows (we used to be a .NET based Software only – so everyone has Windows machines) – (https://www.virtualbox.org/)
Mint 64 bit (my home setup): not as detailed as the Ubuntu version – so if you get stuck refer to that one
Sharing of the code folder between Windows host and Linux virtual machine:
Setup local account on windows machine.
Share code folder on windows machine – ensure that the local account you just created has both read and write.
Go to /home/<linux_username> and mkdir sourcecode (or whichever name you prefer)
Go to Linux and edit /etc/fstab (for instance sudo gedit /etc/fstab should do the trick)
Add the following at the bottom of the file (there are not supposed to be any line breaks in the command, white spaces are important, and commas likewise)
What editor to use?: Have not decided completely yet, but currently I am considering:
sublime text. I am testing right now, and so far it has really blown my mind – install the intellisence package to get the full power.
Webstorm. I have been using for JavaScript for a while and I simply love it, so it says something about the promise of sulime 2 that I am testing it right now.
That is it for now… Will write more when we have the last details of our environment up and running, such as mongo install and how to structure our nodejs application in folders etc.
For the past half year or so I have been using Backbone. Besides the obvious questions of how to fit the different pieces together, when to use what, and in general understanding the library, I have experimented with different ways of extended the existing Backbone behavior.
Having tried a lot of different methods I ended up using 2 different approaches for 2 different scenarios.
Mixin
You can use the different Backbone modules’ extend function (they all have the same, which is not to be confused with the underscore extend function) to achieve code reuse. For instance if you wanted to create a model with an additional function you could do like this, by extending Backbone.Model:
This is the normal way to use extend on a model, and Backbone will ensure the prototype chain is set up correctly. This is often used to create hierarchy of base models some potentially with many functions leading to a huge object that is used to extend all models from, like:
However, at least in my opinion this is not necessarily a good way of using such a powerful feature. A given model can be extended with a number of features from different objects:
This way it lets you build features in small objects that are easy to test seperately. Basically, creating a model becomes a matter of picking the different features you would like have enabled instead of dragging around a huge “base” model or hierarchy of base model.
There is a couple of problems with this use of the extend method. If the object contains methods with same names the last one to be mixed in (extended with) will overwrite the earlier ones and the prototype chain will be kinda of weird.
Wrapping
I have experimented with a number of ways of decorating the behavior of a Backbone modules, and basically found two feasible paths.
I can make a french bulldog a bulldog without making it a dog.
When I find the definition of a french bulldog I can see all the ways of it.
I have not found anyone else who have done a similar implementation, maybe I have looked the wrong places , maybe I just got it wrong and it is really nice with a mother of all base model, or we really benefit from having a long prototype chain.s
Thankfully, this post if going to be a lot shorter than the good parts, but I think with a bit of improvement Øredev can move from being a very good conference, to a brilliant conference.
The WiFi was a disgrace! Shouldn’t be that hard to get working.
Too many sessions were delayed due to faulty cables, projectors, or other technical problems. With a bit more testing and backup cables, projectors, and such readily available, it should be possible to minimize these kinds of problems.
The venue is quite good due to it’s location very close to the train station, but the structure of the building makes it hard to move from session to session, and at lunch the main area becomes as crowded as a metro in a reasonably sized city.
If this is fixed (at least the first 2 items) and the speaker quality stays high, Øredev 2012 is going to be brilliant.
Comments
Nikolaj K N
Hi Emily,
Really nice to hear from you, means my feedback ended up the right place.
I hope you will be able to push the boundaries of the WiFi even further, and improve the experience for all.
I am looking forward to see it and will be sure to test it again next year.
Best Regards
/Nikolaj
Emily Holweck
Hi,
as the organiser of the event, I want to answer your post :) I did read the nice post as well and thank you for both your posts!!!! I asked our technician Andreas, who has done a fantastic job, why we have so many difficulties with the network, here is his answer:
"I was checking the wifi in different locations every day several times and got good throughput (10mbs/11mbs). We build a completely new hotspot network in 1½ week, The building it self is made of stonewalls and there is allot of steel frameworks in the building so we tried to fine tune the radio during the conference.
The wifi on the paper should handle more than 5000 simultaneous connections, it was the hotspots itself that where the bottleneck and we placed about 20 of those and they should hold 256 simultaneous connections each. The backend delivers more than 3Gbit throughput and up to 500.000 packets per second."
Well, it is not that easy! I hope we can improve next year. And I hope you will visit us again!
Kind regards, Emily Holweck, Öredev AB
rafek
That's funny because last year I wasn't able to actually connect to the WiFi with my Samsung smartphone.. but this year, the very same Samsung and I tweeted all the time :)
Nikolaj K N
My recollection is that it was bad last year as well (albeit I recall it as being slightly better back then). Either way I don't think it was good enough. To compare at the GotoCON conference in Copenhagen this year I experienced almost no problems with the WiFi
The Øredev conference 2011 is now over and at this point I have even managed to catch up on missing sleep and cut down on the coffee usage!
As usual the conference was a success (from my perspective) with brilliant speakers and interesting topics, and this is my presentation of the good parts.
Monday
This day I was fortunate enough to have TDD training with Corey Haines. We started out with a simple code kata, and quickly more followed, which were solved in pairs or alone.
During these exercises the Transformation Priority Premise was introduced, something I originally discovered when Uncle Bob invented it a while ago. Didn’t really get it back then, but now at least I get the concept and can apply it albeit clumsily.
In the late afternoon Corey spoke a bit about Mocking and general challenges encountered by the different attendants. Even though, I did get a lot of value from this part it did at times seem unstructured and slightly random.
In general a very good day, and maybe next time Corey will have a Mocking kata up his sleeve in the event that it is requested?
Tuesday
Another day of training, this day I attended the Git Bootcamp with Matthew J. McCullough. I have been using Git for a few months now with a central SVN repository, and felt I was ready to move to the next level.
With the energetic guidance of Matthew the entire room was quickly up and running and within a few hours I discovered the first new gem of Git.
Before lunch Matthew promised to show us something truly mind blowing with Git, but unfortunately I had seen the trick before and was slightly disappointed. This got me thinking how fast you become used to Source Control being a welcome tool in your everyday developer life with Git, as opposed to all the pain felt before starting to use Git.
Again a very good day, and I do believe I managed to move to the next level. If you are looking for a day of Git training, this definitely seems like the way to do it.
Wednesday
The conference was properly kicked off with an inspiring keynote from Alexis Ohanian regarding getting your mother away from your website, or was it getting other users than your mother? Seems our business is slowly realizing that all that really matters is the users. Fortunately, there are plenty of companies that have yet to realize and act on this, leaving a ton of opportunities to grab their customers if you execute!
I had really looked forward to seeing Yehuda Katz and both his talk on SproutCore and Rails Serializer were quite brilliant. Very intriguing technique he applied for the first talk having slides with inline JavaScript console – worked quite well, when the dependency on being online was removed.
In the afternoon I hadn’t really figured out what to see, and ended up attending a session on TDD with JavaScript. I expected to see some random Swedish or Danish dude named Christian Johansen, but turned out it was THE Christian Johansen, author of Test-Driven JavaScript Development, creator of Sinon.JS, and Norwegian. This session was the most impressive live coding session I have ever seen with Christian creating a small JQuery plugin in 50 minutes – test driven and everything. Very impressive!
Thursday
This day I started out with watching Greg Young explaining how not to apply CQRS. Greg chose to forego slides and coding, and just slowly wandered back and forth on the stage while visualizing his points with war-stories from the real world. Mainly:
Do not apply CQRS as a top level architecture, creating a monolithic CQRS system. You will fail.
Apply CQRS in a bounded context – but only if the context gives you a competitive advantage. Otherwise you will fail.
Do not create a CQRS framework, at least not before you have implemented CQRS in at least 5 different systems.
I think few speakers have the charisma, memory (no notes), and voice (I am not even sure the mike worked) to pull this off – Greg Young does.
Friday
Unfortunately, I could not attend Friday’s sessions. How was it?
Comments
Alexander Beletsky
That sounds like a great boost you got there).. Øredev is cool, hope some videos will be available soon.
Really nice to hear from you, means my feedback ended up the right place.
I hope you will be able to push the boundaries of the WiFi even further, and improve the experience for all.
I am looking forward to see it and will be sure to test it again next year.
Best Regards
/Nikolaj
as the organiser of the event, I want to answer your post :) I did read the nice post as well and thank you for both your posts!!!!
I asked our technician Andreas, who has done a fantastic job, why we have so many difficulties with the network, here is his answer:
"I was checking the wifi in different locations every day several times and got good throughput (10mbs/11mbs). We build a completely new hotspot network in 1½ week, The building it self is made of stonewalls and there is allot of steel frameworks in the building so we tried to fine tune the radio during the conference.
The wifi on the paper should handle more than 5000 simultaneous connections, it was the hotspots itself that where the bottleneck and we placed about 20 of those and they should hold 256 simultaneous connections each. The backend delivers more than 3Gbit throughput and up to 500.000 packets per second."
Well, it is not that easy!
I hope we can improve next year. And I hope you will visit us again!
Kind regards,
Emily Holweck, Öredev AB